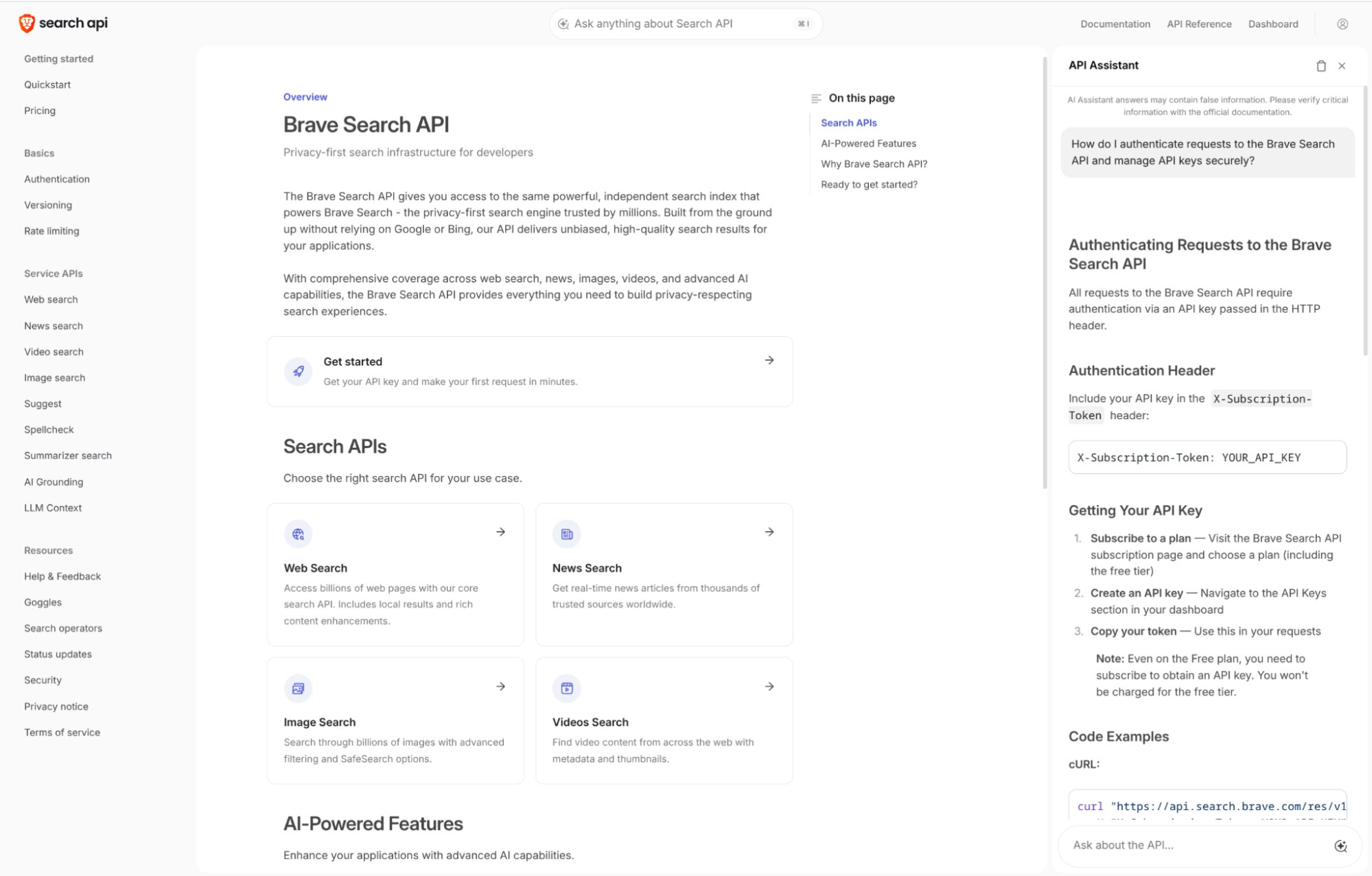
Brave SearchvsExa
Brave wins on speed (669ms vs ~1,200ms), benchmark score (14.89 vs 14.39), MCP breadth (6 tools vs 1), and free tier (2K queries/mo). Exa wins on semantic depth (neural embeddings, people/company/code verticals), weekly downloads (940K vs REST-only), HN traction (412 vs 95 pts), and now deep research (Exa Deep, March 2026). Use Brave as the default; switch to Exa when you need meaning-based search, vertical lookups, or deep research.
Brave SearchvsTavily
AIMultiple benchmark: ~1pt gap (14.89 vs 13.67) described as 'meaningful, not random' — confirmed independently by Data4AI. Brave: independent index (only one after Bing shutdown), SOC 2. Tavily: full platform (search + extract + /research GA), enterprise pricing ($0.0002/query at volume), 1.18M downloads. Meta Llama Stack now defaults to Brave over Tavily. Brave is objectively stronger on search quality; Tavily evolving into a platform play.
FirecrawlvsCrawl4AI
Firecrawl wins on features (search+scrape+agent), enterprise compliance, multi-language SDKs, benchmark score (14.58), success rate (95.3% vs 89.7%), and ScrapeOps rating (10/10 vs 7/10). Crawl4AI wins on license (Apache-2.0 vs AGPL), cost (free at any scale), fork ratio (6,353 vs 6,516 — nearly equal dev usage), and local LLM support. Crawl4AI actively maintained — v0.8.5 released March 18.
ExavsTavily
Exa wins on quality (14.39 vs 13.67 Agent Score, 81% vs 71% complex retrieval, 96% vs 85% citations), neural index, and now deep research (Exa Deep). Tavily wins on distribution (1.18M weekly downloads, LangChain default), response time (187ms), and full platform breadth (search+extract+research GA). Exa is the better tool; Tavily is the more convenient one. Both have strategic risk — Tavily's Nebius acquisition, Exa's Deep claims unverified.
FirecrawlvsJina Reader
Firecrawl does everything Jina Reader does, plus search, structured extraction, batch processing, and agent endpoint. Jina Reader's OSS repo is stale (no commits for 10+ months). Firecrawl is the superset choice for new projects. Firecrawl 4-5x cheaper at volume.
SearXNGvsBrave Search
SearXNG: free, self-hosted, private, 70+ aggregated engines. Brave: higher quality (14.89 benchmark), faster (669ms), managed, SOC 2. Privacy vs quality tradeoff. SearXNG is the only option for teams that can't send queries to third-party APIs.
Parallel AIvsPerplexity Sonar
Both serve deep research. Parallel: 48% BrowseComp vs Perplexity 8%. Both slow (13,600ms vs 11,000ms+). Parallel delivers on depth; Perplexity has higher raw accuracy (87% HumAI) but truncation issues. Parallel wins on deep research quality if you can tolerate latency and cost.