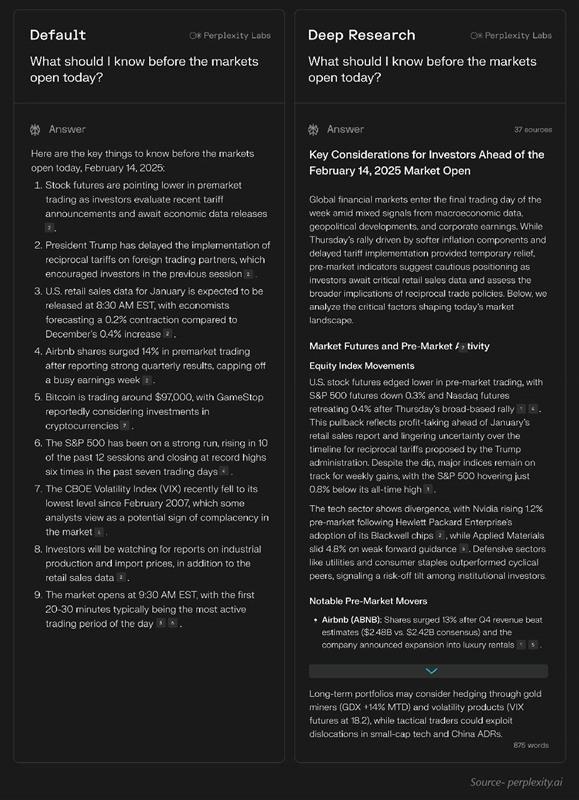
Perplexity Deep ResearchvsOpenAI Deep Research
Perplexity wins on speed (15-30s vs 3-15 min), citation quality, SimpleQA accuracy (93.9%), and price ($20 vs $200). OpenAI wins on expert reasoning (HLE 26.6% vs 21.1%) and GAIA (72.57%). Use case dependent: speed vs depth.
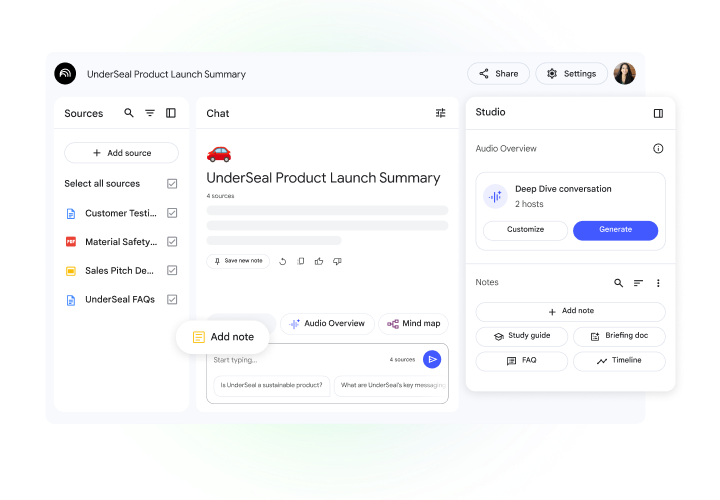
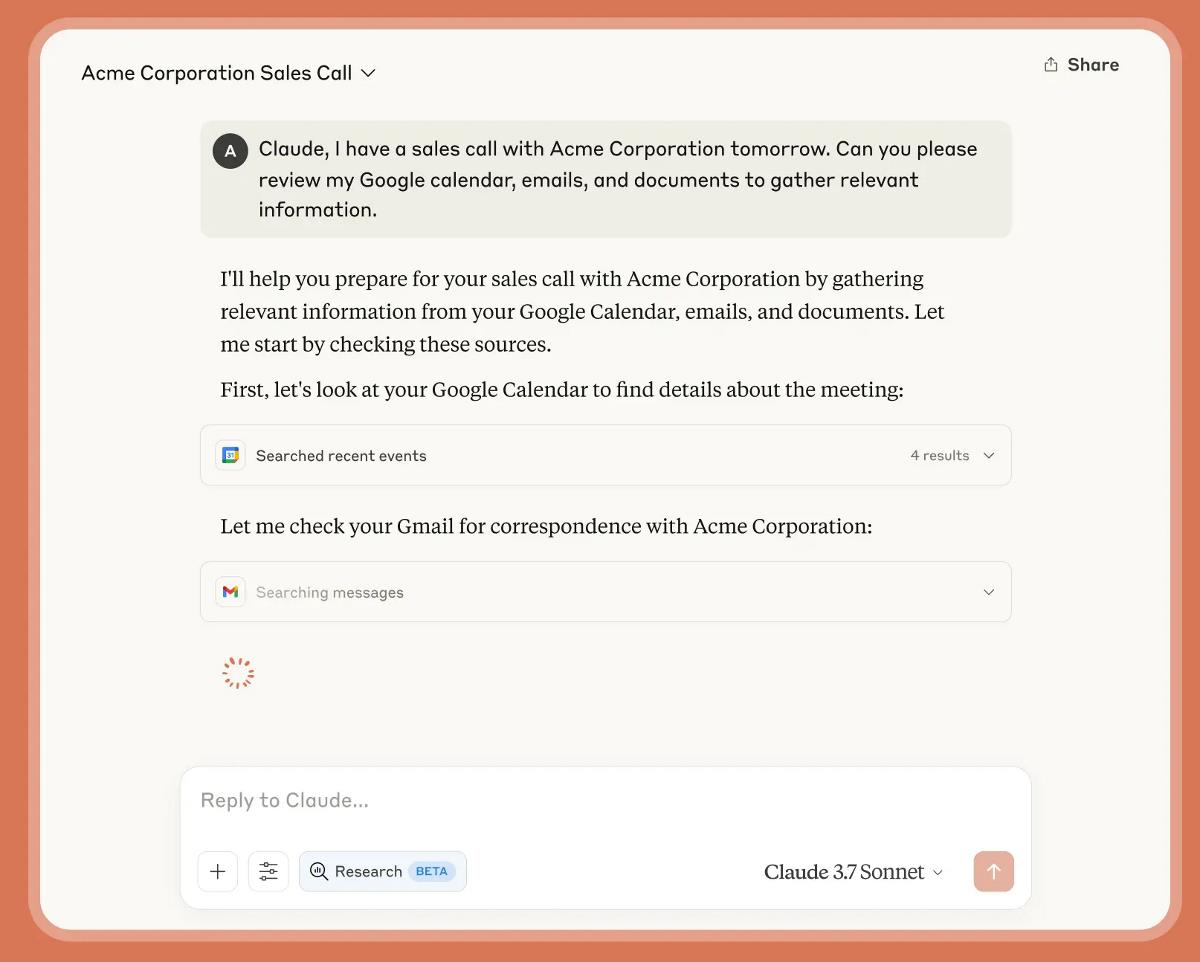
Google NotebookLMvsPerplexity Deep Research
Google leads on source coverage (100+ vs 10-30), multimodal (video/audio/PDF), and HN buzz (907 vs 368 pts). Perplexity leads on speed and citation quality. NotebookLM is a research workbench; Perplexity is a fast answer engine.
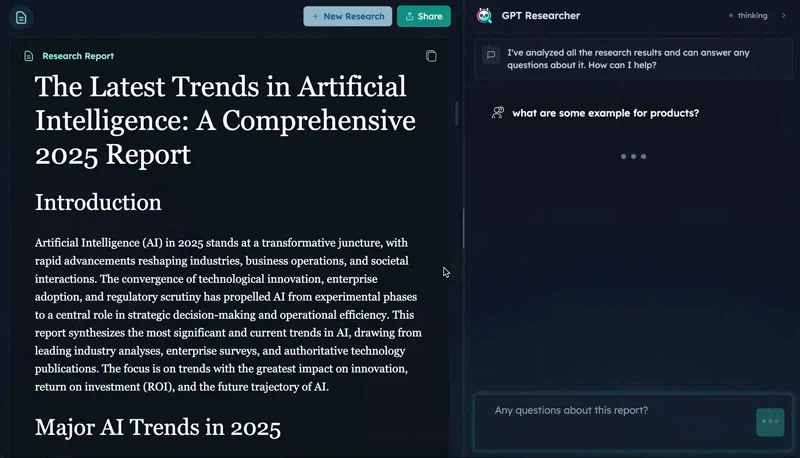
GPT ResearchervsTongyi DeepResearch
GPT Researcher has proven CMU benchmark validation and real PyPI adoption (15.9K/wk). Tongyi has superior benchmark scores (HLE 32.9 vs N/A) and runs locally. GPT Researcher = established leader; Tongyi = disruptive newcomer.
STORM (Stanford)vsGPT Researcher
STORM produces better structured Wikipedia-style articles with peer-reviewed citation quality (85.2% precision). GPT Researcher is more practical for agentic research workflows with MCP integration. STORM = knowledge artifacts; GPT Researcher = research pipelines.
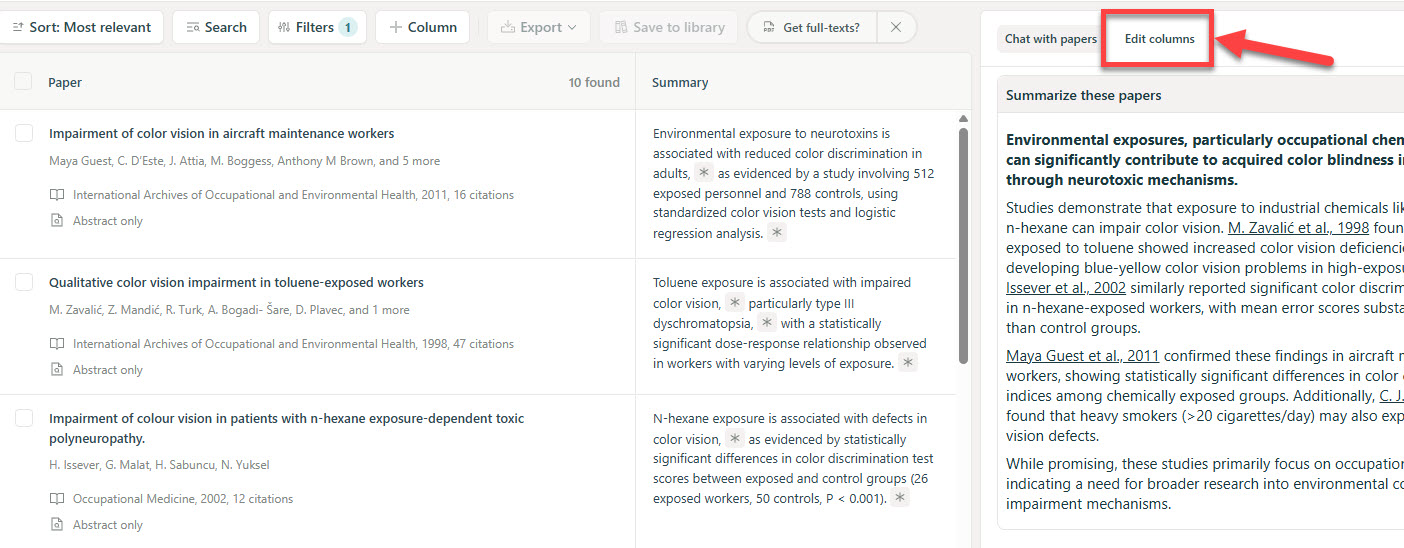
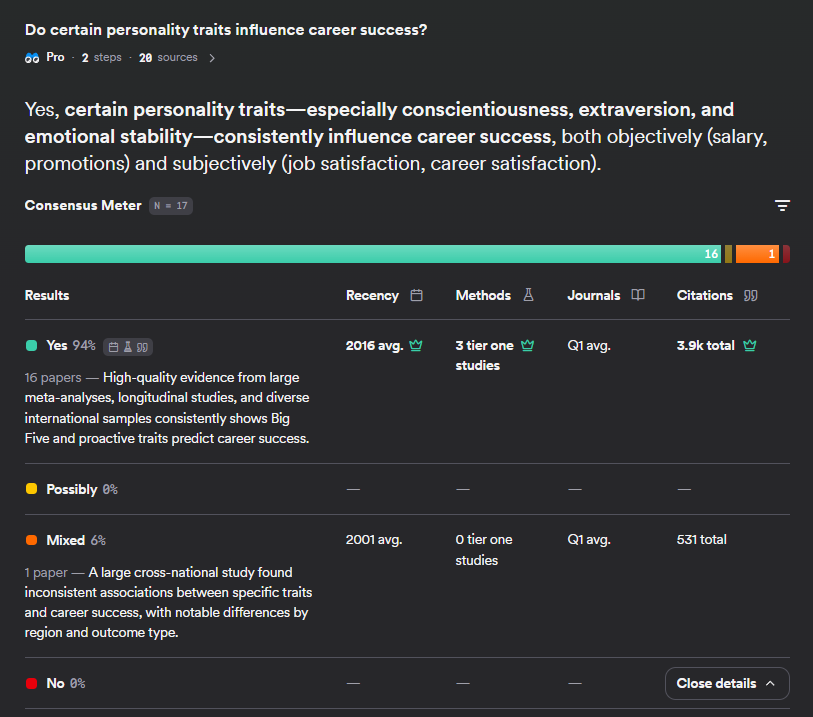
ElicitvsConsensus
Elicit wins for deep academic workflows (systematic reviews, data extraction, API). Consensus wins for quick claim-level evidence checking with unique consensus meter. Complementary rather than competitive.