Ranking update2026-03
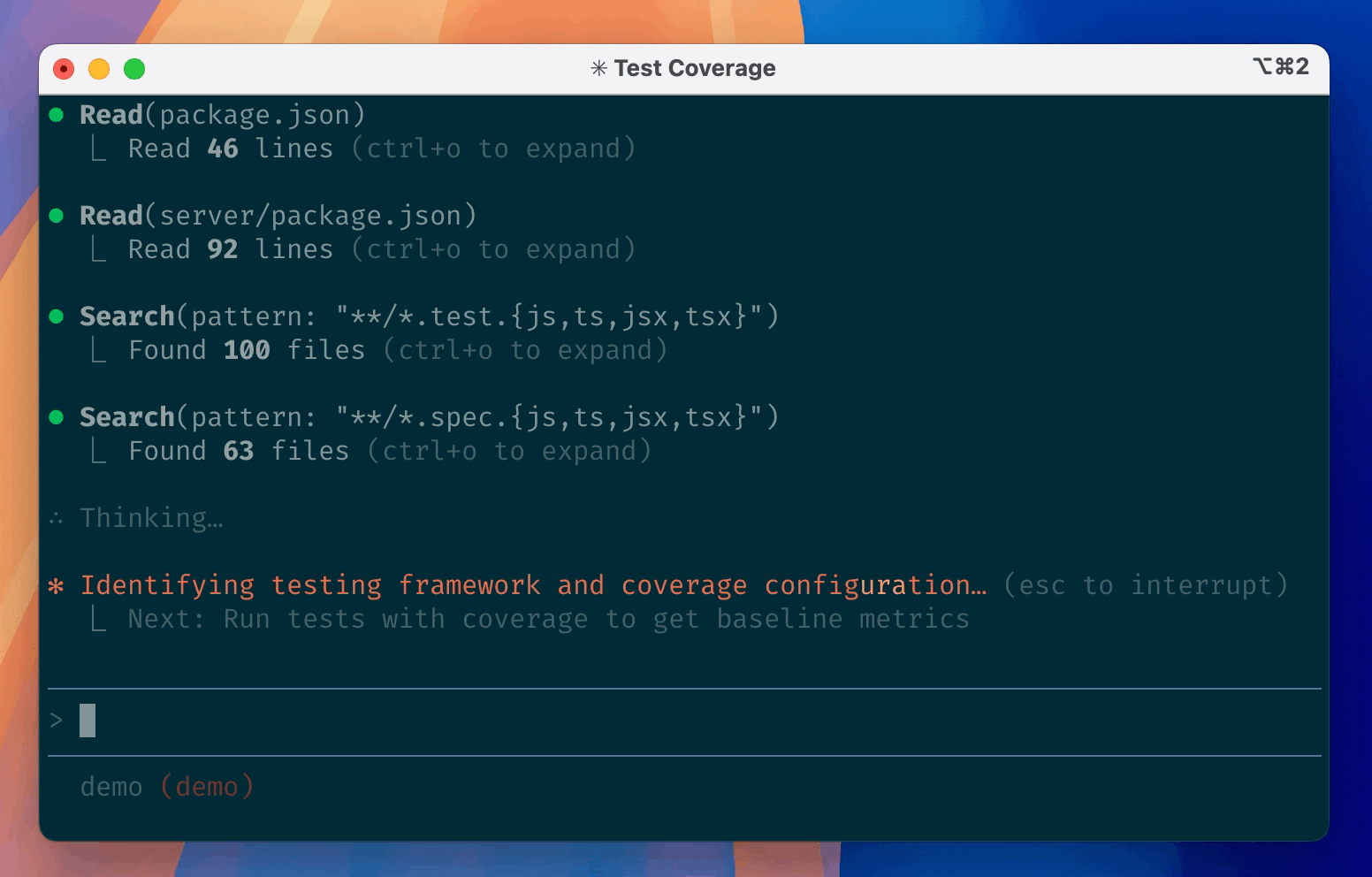
Gemini CLI #2, Copilot CLI #3 after March 25 signal runWeekly Gemini releases (v0.35.0) plus doc-confirmed 1M context / 1K free requests elevated it above Codex. Copilot CLI’s v1.0.11 release, 185-upvote Reddit GA thread, and GitHub demo tweet pushed it to #3 despite <10K stars.
Release cadence2026-03
Claude Code v2.1.81 adds `--bare` and smarter MCP OAuth100 commits between Jan 29 and Mar 20 (~14/week, 10+ maintainers) underpin the release that shipped `--bare`, improved worktree resume, and richer MCP OAuth — a key reason Claude keeps the top slot.
Reliability watch2026-01
HN outage thread (46532075) + issue #16673 resolved fast181-point thread captured a v2.1.0 startup failure; maintainers patched it immediately (GitHub issue #16673). We track these regression cycles because Claude’s trust premium only holds if fixes stay public and fast.
Security watch2026-02
PromptArmor exploit shows Copilot CLI downloading payloadsAttackers can pipe `env curl ... | env sh` straight into Copilot CLI without approval. The 62-point HN thread (47183940) amplified it — enterprise rollouts need network policies or sandboxes ready.
Adoption signal2026-03
Copilot CLI GA thread hits 185 upvotes on r/GithubCopilotCommunity reproduced GitHub’s GA repo to demo `/clear`, MCP configs, and Autopilot. Small but real usage signal that balances the security watchlist.
Orchestration layer2026-02
Emdash Show HN hits 206 points — 21 supported CLIsPre-warmed git worktrees (<1s startup), SSH remotes, and first-class support for Claude, Codex, Gemini, Droid, Amp, etc. make it the leading ADE for juggling ranked CLIs.
Orchestration layer2025-12
Superset isolates git worktrees + live agent notificationsMulti-worktree multitasking (Codex/Claude/Gemini) with push notifications when an agent finishes and spotlighted terminals. Teams report 2-3× faster runs — on-prem alternative to Emdash.
Memory layer2026-01
Grov proxy shares agent reasoning, cuts tokens 50–70%Preview→expand memory capture feeds Claude/Gemini/Codex sessions with team knowledge while drift detection intervenes mid-task. Addresses the persistent context gap in CLI workflows.
Catalog correction2026-03
OpenCode demoted to Watch — two security incidents, controversy-driven star surge126K+ stars are real but driven by Anthropic OAuth controversy. CVE-2026-22812 (CVSS 8.8-10.0) is a second security incident after the unauthenticated RCE (fixed v1.1.10+). Two serious security incidents make trust story the weakest in category. Drops from #5 to Watch list.
Benchmark verified2026-03
Terminal-Bench 2.0: Gemini CLI #1 (78.4%), Codex CLI #2 (77.3%), Claude Code #3 (74.7%)Terminal-Bench 2.0 results: Gemini CLI leads terminal-native tasks at 78.4%, Codex CLI close at 77.3%, Claude Code at 74.7%. All three are competitive — gap between #1 and #3 is only 3.7pp.
Trust flag2026-03
Claude Code CVEs: CVE-2025-59536 (CVSS 8.7) and CVE-2026-21852 — both patchedTwo patched security incidents: hooks injection RCE (fixed v1.0.111) and API token exfiltration (fixed). Codex CLI has the cleanest security record in Tier 1 — zero documented incidents.
Quality signal2026-03
First-pass correctness gap: Claude Code ~95% vs Gemini CLI ~50-60% (Educative.io)Educative.io practical test: Claude Code ~95% first-pass correctness vs Gemini CLI ~50-60%. This 2x quality gap is wider than SWE-bench Pro scores suggest. Practical quality is weighted heavily in this ranking.
New entrant promoted2026-03
OpenHands promoted to #5 — 69K stars, $18.8M Series A, Docker-sandboxed execution69K stars (#2 among agents), Docker-sandboxed Kubernetes environments, model-agnostic with MCP support. CLI release Feb 2026. Planning Agent with Plan/Code mode. Cloud-first adds latency vs terminal-native tools.
Benchmark caveat2026-03
METR: ~50% of SWE-bench-passing PRs would NOT be merged by real maintainersMETR's March 2026 study: ~50% of SWE-bench-passing PRs would NOT be merged. A 46% SEAL score ≈ 23% 'would actually ship' rate. Practical quality signals (first-pass correctness, switching patterns) carry weight in this ranking.
Scaffold insight2026-03
Morphllm: 'same model can score 17 problems apart in different agents'Morphllm independent test of 15 agents: scaffold maturity gap is 17 problems on same model. Claude Code named 'best AI coding agent for most developers.' Codex CLI's custom scaffold (56.8%) vs SEAL standardized (41.04%) illustrates the gap.
Hybrid pattern2026-03
Emerging consensus: Claude Code for planning, Codex CLI for implementationMultiple independent sources converge on using Claude Code for planning/architecture and Codex CLI for implementation. Not a compromise — may be the optimal workflow.
Usage signal2026-03
SemiAnalysis: Claude Code at ~4% of GitHub public commits, $2.5B annualized revenue~4% of public GitHub commits, projected 20%+ by EOY 2026. 42,896x growth in 13 months. $2.5B annualized revenue. 8M+ npm weekly downloads — 3x Codex, 12x Gemini.
Quality monitoring2026-03
MarginLab: no Claude Code degradation detected (p<0.05)Independent daily monitoring with 56% baseline pass rate and no statistically significant degradation. Quality regression perception (1,085 HN pts) is community sentiment, not measured reality.