Constrained peek so you can sanity-check the source material without leaving the site.
<div align="center" id="top">
<img src="https://github.com/assafelovic/gpt-researcher/assets/13554167/20af8286-b386-44a5-9a83-3be1365139c3" alt="Logo" width="80">
English | 中文 | 日本語 | 한국어
</div>
🔎 GPT Researcher
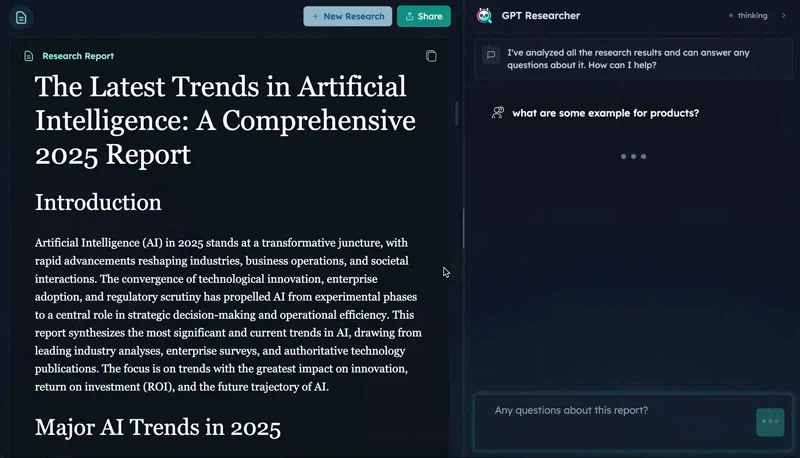
GPT Researcher the first open deep research agent designed for both web and local research on any given task.
The agent produces detailed, factual, and unbiased research reports with citations. GPT Researcher provides a full suite of customization options to create tailor made and domain specific research agents. Inspired by the recent Plan-and-Solve and RAG papers, GPT Researcher addresses misinformation, speed, determinism, and reliability by offering stable performance and increased speed through parallelized agent work.
Our mission is to empower individuals and organizations with accurate, unbiased, and factual information through AI.
Why GPT Researcher?
- Objective conclusions for manual research can take weeks, requiring vast resources and time.
- LLMs trained on outdated information can hallucinate, becoming irrelevant for current research tasks.
- Current LLMs have token limitations, insufficient for generating long research reports.
- Limited web sources in existing services lead to misinformation and shallow results.
- Selective web sources can introduce bias into research tasks.
Demo
<a href="https://www.youtube.com/watch?v=f60rlc_QCxE" target="_blank" rel="noopener">
<img src="https://github.com/user-attachments/assets/ac2ec55f-b487-4b3f-ae6f-b8743ad296e4" alt="Demo video" width="800" target="_blank" />
</a>
Install as Claude Skill
Extend Claude's deep research capabilities by installing GPT Researcher as a Claude Skill:
npx skills add assafelovic/gpt-researcher
Once installed, Claude can leverage GPT Researcher's deep research capabilities directly within your conversations.
Architecture
The core idea is to utilize 'planner' and 'execution' agents. The planner generates research questions, while the execution agents gather relevant information. The publisher then aggregates all findings into a comprehensive report.
<div align="center">
<img align="center" height="600" src="https://github.com/assafelovic/gpt-researcher/assets/13554167/4ac896fd-63ab-4b77-9688-ff62aafcc527">
</div>
Steps:
- Create a task-specific agent based on a research query.
- Generate questions that collectively form an objective opinion on the task.
- Use a crawler agent for gathering information for each question.
- Summarize and source-track each resource.
- Filter and aggregate summaries into a final research report.
Tutorials
- How it Works
- How to Install
- Live Demo
Features
- 📝 Generate detailed research reports using web and local documents.
- 🖼️ Smart image scraping and filtering for reports.
- 🍌 AI-generated inline images using Google Gemini (Nano Banana) for visual illustrations.
- 📜 Generate detailed reports exceeding 2,000 words.
- 🌐 Aggregate over 20 sources for objective conclusions.
- 🖥️ Frontend available in lightweight (HTML/CSS/JS) and production-ready (NextJS + Tailwind) versions.
- 🔍 JavaScript-enabled web scraping.
- 📂 Maintains memory and context throughout research.
- 📄 Export reports to PDF, Word, and other formats.
📖 Documentation
See the Documentation for:
- Installation and setup guides
- Configuration and customization options
- How-To examples
- Full API references
⚙️ Getting Started
Installation
-
Install Python 3.11 or later. Guide.
-
Clone the project and navigate to the directory:
git clone https://github.com/assafelovic/gpt-researcher.git
cd gpt-researcher
-
Set up API keys by exporting them or storing them in a .env file.
export OPENAI_API_KEY={Your OpenAI API Key here}
export TAVILY_API_KEY={Your Tavily API Key here}
(Optional) For enhanced tracing and observability, you can also set:
# export LANGCHAIN_TRACING_V2=true
# export LANGCHAIN_API_KEY={Your LangChain API Key here}
For custom OpenAI-compatible APIs (e.g., local models, other providers), you can also set:
export OPENAI_BASE_URL={Your custom API base URL here}
-
Install dependencies and start the server:
pip install -r requirements.txt
python -m uvicorn main:app --reload
Visit http://localhost:8000 to start.
For other setups (e.g., Poetry or virtual environments), check the Getting Started page.
Run as PIP package
pip install gpt-researcher
Example Usage:
...
from gpt_researcher import GPTResearcher
query = "why is Nvidia stock going up?"
researcher = GPTResearcher(query=query)
# Conduct research on the given query